2012
Web Sémantique, Google Knowledge Graph & Startups – Interview Milan Stankovic

Peux-tu te présenter en quelques mots ?
 Je suis spécialiste du Web Sémantique. Cela fait 6 ans que je travaille dans ce domaine, plus précisément dans l’intersection du Web Sémantique et du Web 2.0. Je suis aussi Directeur R&D d’une start-up parisienne, Hypios.com, qui a produit une plate-forme d’innovation en ligne.
Je suis spécialiste du Web Sémantique. Cela fait 6 ans que je travaille dans ce domaine, plus précisément dans l’intersection du Web Sémantique et du Web 2.0. Je suis aussi Directeur R&D d’une start-up parisienne, Hypios.com, qui a produit une plate-forme d’innovation en ligne.
Peux-tu nous parler de tes projets ?
Mes projets concernent principalement le développement des outils informatiques, basés sur le Web Sémantique, qui sont utiles dans un contexte industriel. Au sein d’hypios nous avons besoin de technologies avancées pour aider à faire émerger l’innovation sur le Web. De nombreux acteurs d’innovation sont présents sur le Web : des entreprises qui souhaitent innover, des experts, des chercheurs, etc. Si un simple site Web peut facilement permettre à ces acteurs de s’inscrire et collaborer, faire en sorte qu’ils se découvrent les uns et les autres, d’une manière pertinente, est un défi plus important que mon département R&D cherche à relever.
Par exemple, nous accordons beaucoup d’importance à la recherche d’experts sur le Web afin de permettre aux entreprises d’accéder aux connaissances et savoir-faire externes. Sur le Web nous trouvons beaucoup de traces de l’activité des experts sous formes différentes, ex. des articles scientifiques, des blogs, des réponses sur des sites comme Quora etc. Toutes ces traces sont des témoins d’une certaine connaissance. Mais comment la mesurer ? La représentation sémantique de traces nous permet de nuancer nos métriques d’expertise. Nous détectons les types de traces les plus pertinentes pour chaque sujet d’expertise qui nous intéresse, et nous suivons en permanence l’évolution des communautés d’experts en ligne et de leurs pratiques d’échange afin de mieux identifier les vrais experts. Les formats de données riches, soutenus par des standards du Web Sémantique, nous ont permis de mettre en place une approche souple, très facilement.
La recherche d’experts n’est qu’un exemple. Vous pouvez trouver plus de renseignement sur les projets récents sur mon site milstan.net et sur research.hypios.com.
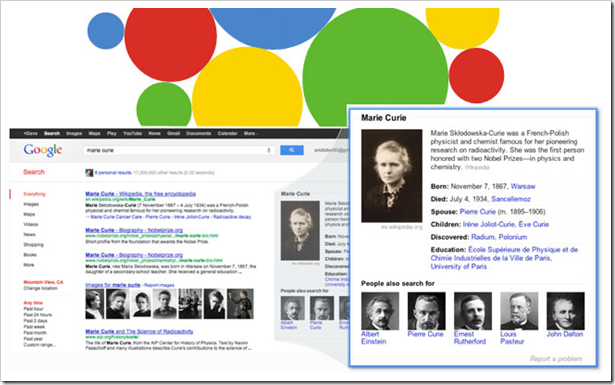
Google améliore son service avec Google Knowledge Graph, peux-tu nous expliquer l’enjeu de cette technologie ?
C’est en effet une question d’actualité. Knowledge Graph, qui vient d’être rendu disponible aux utilisateurs en France le mois dernier, est effectivement basé sur une technologie du Web Sémantique. De quoi s’agit-il ? Aujourd’hui, en résultat d’une recherche Web, Google ne donne pas seulement des liens vers des pages Web, mais propose aussi des faits. Si on cherche « Marie Curie », nous allons obtenir, à coté des résultats standards, la photo de Marie, des faits comme par exemple sa date et ville de naissance. Ces données s’affichent comme un tableau et ressemblent aux informations qu’on trouve sur Wikipedia. Google se base sur une base de faits pour délivrer ce service. Cette base est, à ma connaissance, le fruit des travaux qui ont suivi le rachat de Freebase, une base de connaissances sémantiques. C’est sans doute un premier pas vers un moteur de recherche sémantique.
Un moteur vraiment sémantique utilisera cette base de connaissances pour aller plus loin et donner des réponses directes à des questions de l’utilisateur. Par exemple, si l’utilisateur cherche la liste des magazines de modes dont les fondateurs sont des citoyennes français, sur un moteur de recherche classique cela peut lui prendre des heures pour les retrouver. Il doit consulter les sites des magazines, trouver des fondateurs, s’assurer qu’ils sont français… Grâce à une base de faits, un moteur sémantique peut donner des réponses instantanées.
Quelque chose comme Wolfram Alpha ?
Exactement. Wolfram Alpha utilise en effet une base de connaissances sémantiques, mais s’appuie principalement à ses propres données sans trop utiliser le Web publique. Google s’appuie sur les données structurées publiques qui composent le Web Sémantique, et dont la quantité est de plus en plus grande.
D’après toi, Comment Google va mêler Web Sémantique et liens sponsorisés ?
Le Web Sémantique signifie simplement que les informations que Google fournit aux utilisateurs seraient plus pertinentes. Les utilisateurs vont donc pouvoir passer plus de temps chez Google. En explorant le Knowledge Graph, les utilisateurs vont en fait mieux exprimer leurs intentions, et Google va avoir plus d’informations sur ce que les utilisateurs cherchent vraiment. Leurs clics parleront plus que des mots-clés fournis dans le « search bar ». Google va donc pouvoir mieux cibler des liens sponsorisés et augmenter le taux de clics. Mais la recherche sémantique peut s’appliquer sur tout type de données. Elle peut être utile pour faciliter l’accès aux informations au sein d’une entreprise ; et dans plein d’autres cas d’utilisation.
N’y a-t-il pas un risque à trouver des réponses sans recherche approfondie ?
En effet, nous ne pouvons pas écarter cette possibilité, mais ce risque existait bien avant le Knowledge Graphe. Et pourtant, Google a toujours trouvé (et il trouvera toujours) des moyens pour profiter de l’attention que les utilisateurs lui accordent. Même s’ils trouvent ce qu’ils cherchent directement dans le Knowledge Graph, il est toujours possible d’intéresser les utilisateurs par des suggestions pertinentes et capter leur attention. Le Web Sémantique est notamment utile pour assurer la pertinence de suggestions. Je n’ai donc pas peur pour Google ![]()
Que peut apporter la recherche sémantique dans le développement de startups ?
Un avantage compétitif, sans doute. Le Web Sémantique, du point de vue de l’industrie, reste une technologie relativement nouvelle. Il y a donc assez peu de produits existants qui l’utilisent et son applicabilité est très grande – il y a donc de la place pour pleins de produits utiles dans différents domaines.
En conséquence de la nouveauté de la technologie, il y a encore assez peu de brevets dans ce domaine. Nous avons donc toujours la liberté d’innover et il est toujours possible de bien se positionner.
Il y a beaucoup de startups qui ne sont même pas conscientes que cela puisse les aider. Imaginons par exemple les applications mobiles. L’utilisateur est là dans une situation différente par rapport aux applications Web classiques – il est souvent pressé, il ne souhaite pas passer du temps à chercher. S’appuyer sur une base sémantique peut permettre de lui fournir des réponses directes à la place des résultats de recherche, quel que soit le domaine de l’application. De la recommandation de films, à la recommandation de restaurants, etc. Nous pouvons imaginer des requêtes de type : restaurant végétarien avec terrasse au soleil à 500m de chez moi…
As-tu des exemples d’applications qui utilisent la technologie du Web Sémantique ?
Je vous donne l’exemple d’une application que j’ai créée et que nous utilisons chez Hypios. Il s’agit de hyProximity, un moteur de suggestion de mots-clés pertinents et inattendus. Sur notre plate-forme d’innovation, nous avons la nécessité de trouver des experts provenant de domaines assez différents pour faciliter le transfert de connaissances d’un domaine à un autre. Pour un problème d’innovation, posé par une entreprise, nous cherchons donc à découvrir des champs de compétences pertinentes, mas assez diverses, souvent faisant parties de disciplines très différentes.
Pour y parvenir, notre outil utilise des bases de connaissances similaires à ceux qui alimentent le Knowledge Graph de Google. Contrairement à Google, notre système ne s’intéresse pas directement aux faits qui sont dans la base, mais plutôt aux liens dans le graphe et donc à la proximité de sujets dans ce graphe. Ainsi, nous arrivons à détecter des sujets proches, mais assez divers. Il existe des systèmes de suggestions de mots-clés basés sur la statistique, mais leurs résultats, souvent même pertinents, souffrent d’une certaine banalité car ils proposent des sujets très similaires, souvent abordés ensemble dans les textes en ligne. Nos résultats arrivent à surprendre, inspirer et enrichir l’utilisateur tout en restant pertinents. C’est une valeur ajoutée.
Quels sont les perspectives d’évolutions après le Web Sémantique ?
D’abord, la guerre pour le Web Sémantique n’est pas finie. Si après 10 ans de travaux de recherche dans ce domaine nous voyons cette technologie en marche, implémenter dans une des applications les plus utilisées au monde, tel que Google, c’est une victoire ! Mais, ce n’est qu’un début d’industrialisation de cette discipline qui va changer la vie des utilisateurs dans pleins de situations différentes. Avec l’émergence de l’Open Data, avec de plus en plus de données en ligne, l’avenir du Web Sémantique, en tant que discipline industrielle, est certaine. À mon avis, il serait notamment intéressant de voir ce que le traitement de données sémantiquement structurés peut apporter dans le e-tourisme, dans la veille technologique, et pour les assistants personnels (comme Siri par exemple).
Mes perspectives, après avoir fini la rédaction de ma thèse de doctorat, sont sans doute de continuer à créer des solutions basées sur le Web Sémantique et sur d’autres technologies émergentes. Chez Hypios, nous avons déjà fait beaucoup, et nous continuons à faire évoluer les solutions basées sur le Web Sémantique dans le domaine de l’innovation en ligne. Dans mon temps libre, je conseille également d’autres start-ups de la région Parisienne qui souhaitent mettre leurs pieds dans cette aventure de traitement de données sémantiques et en faire un avantage compétitif.
Et en ce qui concerne la question de ce qui viendra « après le Web Sémantique » je vous invite à lire les conclusions de ma thèse qui sera publique d’ici décembre. Certaines réponses y seront – l’avenir du Web s’annonce très intéressant.
Articles complémentaires :
Restez branché sur la Startup Academy en vous abonnant directement par email
Pas de commentaires encore
Poster un commentaire